


On June 30, more than 120 real patients, 10 attending and above physicians from West China Hospital of Sichuan University, Chengdu Haier Sen Hospital, and MedGPT AI doctors conducted a consistency assessment between AI doctors and real doctors.

The results of the evaluation showed that the MedGPT AI doctor and the real attending doctors had a 96% agreement on the score results. The real doctor scored a composite score of 7.5, and the AI doctor scored a composite score of 7.2.
MedGPT, a Chinese medical large language model based on the Transformer architecture independently developed by digital healthcare company MedLinker, mainly focusing on exerting actual diagnostic and treatment value in real medical scenarios, aiming to realize the value of actual diagnosis and treatment in real medical scenarios and to realize the intelligent diagnosis and treatment capability of the whole process of disease prevention, diagnosis, treatment, and rehabilitation.



Experts and professors who scored the MedGPT AI doctors generally agree that MedGPT collects sufficient information through multiple rounds of questioning and promotes the consultation process on the premise of ensuring medical accuracy, so the probability of misdiagnosis and omission is relatively small, and the knowledge coverage of MedGPT is more than that of real doctors who do not have sufficient experience.
China’s implementation of AI medical service is approaching
It is worth mentioning that MedLinker is the first to complete the real-world testing of AI doctors, leading in both domestic and international fields. Generalized large language models have natural flaws in accuracy in the face of medical problems. In the diagnosis stage, generalized large language models tend to give conclusions easily, but for medical applications, consistency, and accuracy are the bottom-line issues.

Wang Lei, head of the MedGPT program at MedLinker, said that MedGPT gives a valid diagnosis by gradually guiding patients to give a full picture of their condition.
In other words, MedGPT realizes active human-computer interaction by analyzing enough information and making medically sound decisions. Its unique combination of natural language macro-modeling AI technology with a range of process tuning and medical consistency checking techniques, as well as RLHF (Reinforcement Learning from Human Feedback), supervised fine-tuning in the model fine-tuning training phase with the participation of a large number of real medical practitioners, improves the model’s ability to characterize the disease and recognize patterns, and ensures medical accuracy. This effectively improves the model’s ability to determine disease characteristics and recognize patterns, ensuring medical accuracy.

Returning to the aforementioned consistency assessment between AI doctors and real doctors, Google has also conducted a similar experiment.
In May this year, Google released the big medical model Med-PaLM 2, which can get 86.5 points in the United States Medical License Examination (USMLE), and is the first big language model to reach the expert level in the USMLE.

However, MedLinker’s MedGPT is based on real-world assessments of real patients, whereas Google’s Med-PaLM is based on answers to standard medical questions. MedLinker’s MedGPT leadership is related to its medical data advantage and years of layout in the field of AI. There are 2 billion medical text data and 8 million clinical consultation data are used for MedGPT training.
Will it change the healthcare landscape?
The aforementioned consistency review, from the start of the consultation to the review of the results, the entire process was broadcast live on the Internet.
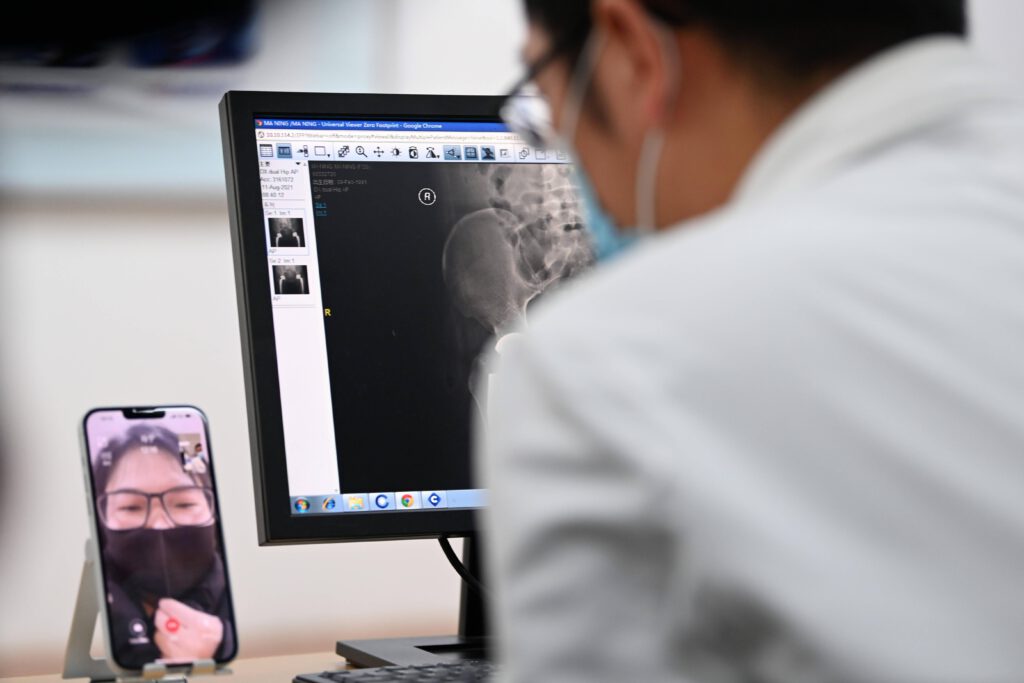
The design of the entire review was quite rigorous, during the consultation process, neither the real doctor nor the AI doctor had direct contact with the patient, the patient communicated with the doctor’s assistant, the doctor’s assistant texted between the real doctor and the AI doctor respectively. After guiding the patient to tell the complete condition and collecting enough decision-making factors, the real doctor and the AI doctor issue a checklist or diagnosis for the patient, and the patient completes the examination directly in hospital; after obtaining the examination results, the patient is then re-examined and provided the clinical diagnosis and treatment plan by the AI doctor and real doctors.
In a way, this is a classic double-blind experiment recognized by the pharmaceutical industry.
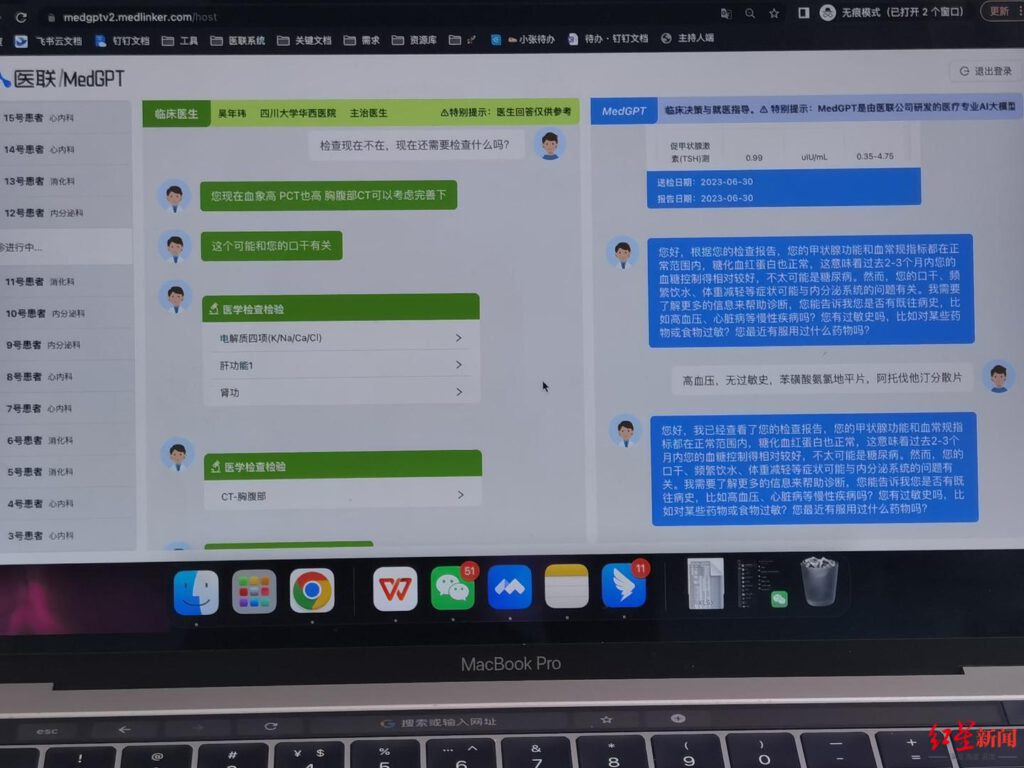
At the end of the 8-hour consultation, 91 valid cases were formed and reviewed by 7 experts and professors from several authoritative hospitals. Specialties evaluated cases in 7 dimensions including accuracy of diagnosis, accuracy of treatment recommendations, accuracy of auxiliary examination protocols, accuracy of data analysis, accuracy of clinical diagnosis and treatment plans, accuracy of examination program, provision of interpretable information, and natural language questioning and interaction.
Xue Feng, chief physician and professor of orthopedics at Peking University People’s Hospital, took a case of knee pain as an example, and he thought that the AI doctor was very patient, careful, and dynamic in consultation, such as paying attention to the preparation and the ongoing situation of pregnancy. Whereas in the reality of clinical work, orthopedic surgeons are likely to ignore these kinds of questions and easily make some mistakes. He also surprisingly found that MedGPT judged that the patient might have nerve compression based on the pain in the sole, which the real doctor did not expect.
Ren Jingyi, chief physician and professor of cardiology at China-Japan Friendship Hospital, gave MedGPT a score that exceeded that of a real doctor, stating, “Although MedGPT still has a lot of problems such as advising over treatment, I think that taking this step forward is considered a milestone result.”
This test is the first public, large-scale, real-patient-based consistency research evaluation of AI doctors and real doctors in China and even globally, and is also a stage-by-stage exploration for AI medical treatment.
It gives a signal that high-quality medical resources and service capabilities can be replicated indefinitely, bringing revolutionary upgrades to the healthcare industry, as well as areas with insufficient and unbalanced healthcare resources.
(Source: MedLinker, Sina, CGTN)
